![]()
來源:圖靈人工智能

前言
代碼寫了那么多�,你知道 a = 1 + 2 這條代碼是怎么被 CPU 執(zhí)行的嗎��?
軟件用了那么多��,你知道軟件的 32 位和 64 位之間的區(qū)別嗎����?再來 32 位的操作系統(tǒng)可以運(yùn)行在 64 位的電腦上嗎?64 位的操作系統(tǒng)可以運(yùn)行在 32 位的電腦上嗎���?如果不行,原因是什么�����?
CPU 看了那么多���,我們都知道 CPU 通常分為 32 位和 64 位�,你知道 64 位相比 32 位 CPU 的優(yōu)勢在哪嗎?64 位 CPU 的計(jì)算性能一定比 32 位 CPU 高很多嗎���?
不知道也不用慌張,接下來就循序漸進(jìn)的�����、一層一層的攻破這些問題���。
正文
圖靈機(jī)的工作方式
要想知道程序執(zhí)行的原理�,我們可以先從「圖靈機(jī)」說起,圖靈的基本思想是用機(jī)器來模擬人們用紙筆進(jìn)行數(shù)學(xué)運(yùn)算的過程,而且還定義了計(jì)算機(jī)由哪些部分組成,程序又是如何執(zhí)行的。
圖靈機(jī)長什么樣子呢�����?你從下圖可以看到圖靈機(jī)的實(shí)際樣子:
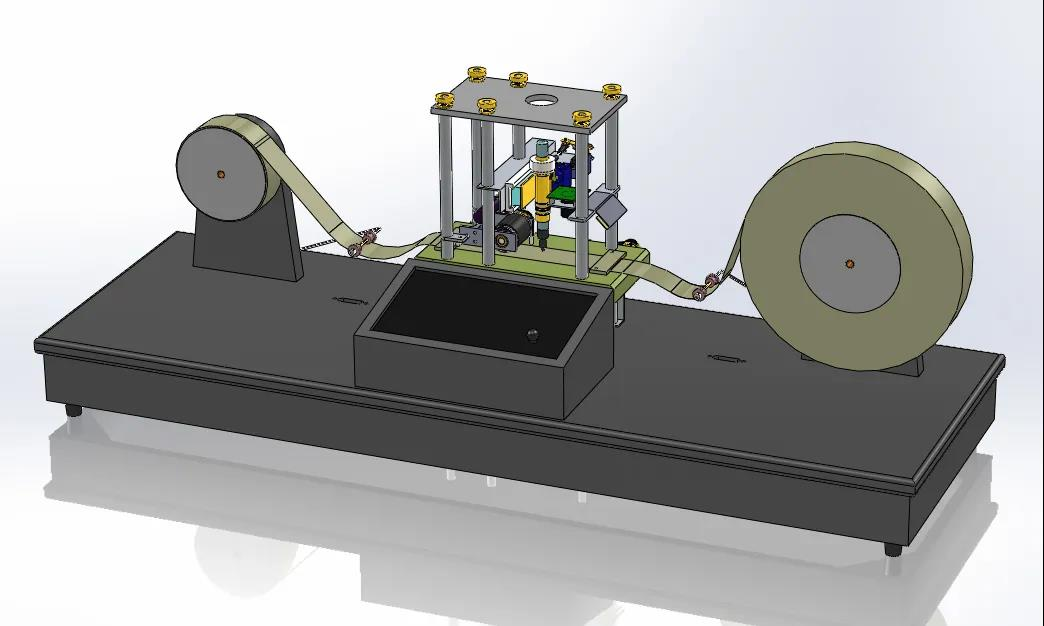
圖來源自:http://www.kristergustafsson.me/turing-machine/
圖靈機(jī)的基本組成如下:
有一條「紙帶」��,紙帶由一個個連續(xù)的格子組成��,每個格子可以寫入字符�����,紙帶就好比內(nèi)存��,而紙帶上的格子的字符就好比內(nèi)存中的數(shù)據(jù)或程序;
有一個「讀寫頭」,讀寫頭可以讀取紙帶上任意格子的字符�,也可以把字符寫入到紙帶的格子�����;
讀寫頭上有一些部件,比如存儲單元、控制單元以及運(yùn)算單元:
1�����、存儲單元用于存放數(shù)據(jù)����;
2、控制單元用于識別字符是數(shù)據(jù)還是指令�,以及控制程序的流程等�����;
3、運(yùn)算單元用于執(zhí)行運(yùn)算指令�;
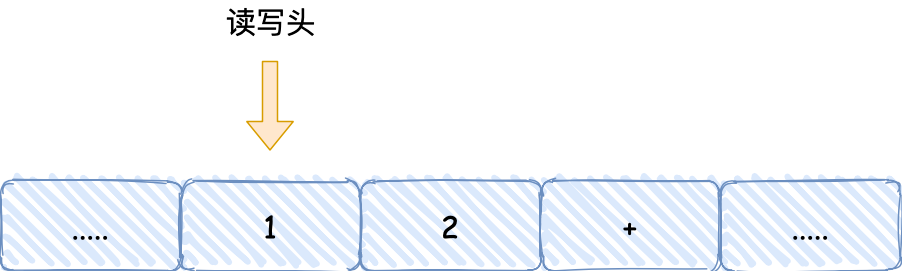
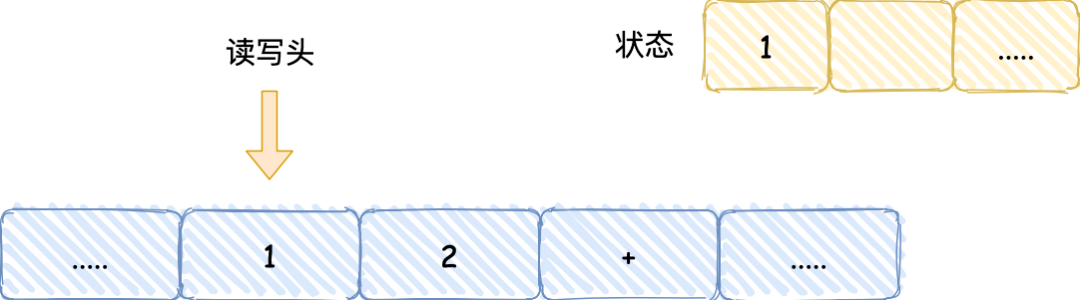
知道了圖靈機(jī)的組成后���,我們以簡單數(shù)學(xué)運(yùn)算的 1 + 2 作為例子�,來看看它是怎么執(zhí)行這行代碼的���。
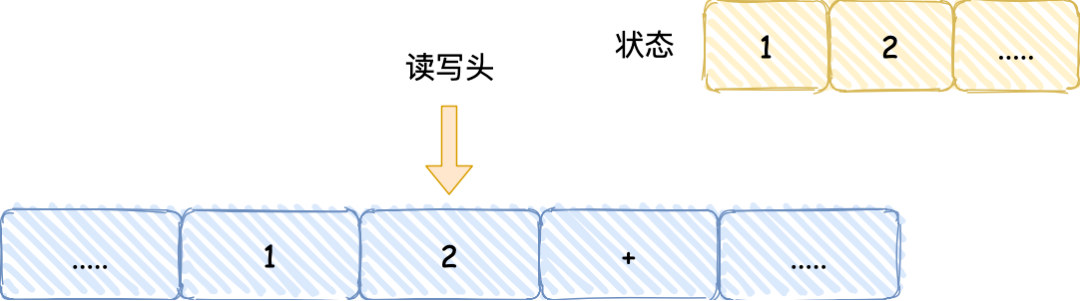

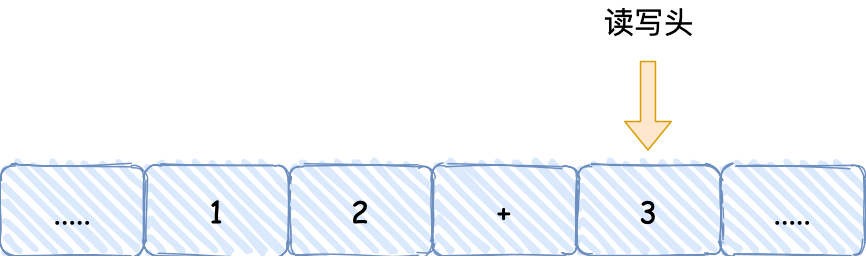
通過
上面
的圖靈機(jī)計(jì)算
1 + 2
的過程,可以發(fā)現(xiàn)圖靈機(jī)主要功能就是讀取紙帶格子中的內(nèi)容�,然后交給控制單元識別字符是數(shù)字還是運(yùn)算符指令���,如果是數(shù)字則存入到圖靈機(jī)狀態(tài)中����,如果是運(yùn)算符�����,則通知運(yùn)算
符單元讀取狀態(tài)中的數(shù)值進(jìn)行計(jì)算���,計(jì)算結(jié)果最終返回給讀寫頭����,讀寫頭把結(jié)果寫入到紙帶的格子中����。
事實(shí)上,圖靈機(jī)這個看起來很簡單的工作方式��,和我們今天的計(jì)算機(jī)是基本一樣的���。接下來���,我們一同再看看當(dāng)今計(jì)算機(jī)的組成以及工作方式���。
馮諾依曼模型
在 1945 年馮諾依曼和其他計(jì)算機(jī)科學(xué)家們提出了計(jì)算機(jī)具體實(shí)現(xiàn)的報(bào)告��,其遵循了圖靈機(jī)的設(shè)計(jì),而且還提出用電子元件構(gòu)造計(jì)算機(jī),并約定了用二進(jìn)制進(jìn)行計(jì)算和存儲�,還定義計(jì)算機(jī)基本結(jié)構(gòu)為 5 個部分���,分別是中央處理器(CPU)���、內(nèi)存���、輸入設(shè)備�、輸出設(shè)備、總線�����。
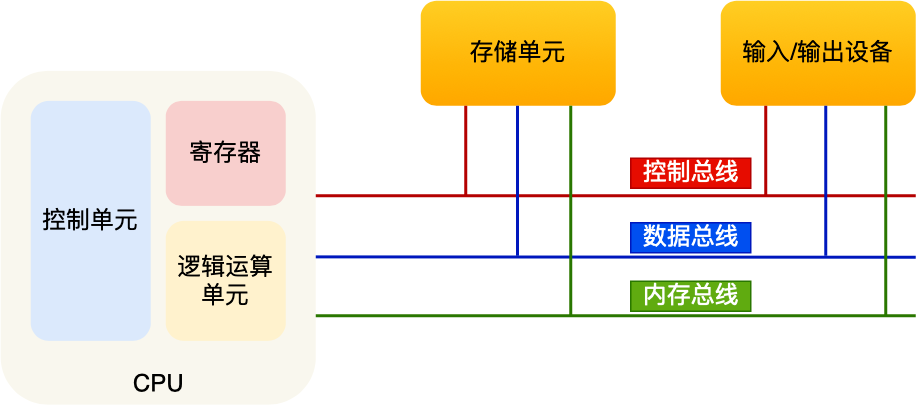
這 5 個部分也被稱為馮諾依曼模型�,接下來看看這 5 個部分的具體作用。
內(nèi)存
我們的程序和數(shù)據(jù)都是存儲在內(nèi)存�,存儲的區(qū)域是線性的�����。
數(shù)據(jù)存儲的單位是一個二進(jìn)制位(bit),即 0 或 1����。最小的存儲單位是字節(jié)(byte)��,1 字節(jié)等于 8 位。
內(nèi)存的地址是從 0 開始編號的�����,然后自增排列����,最后一個地址為內(nèi)存總字節(jié)數(shù) - 1�����,這種結(jié)構(gòu)好似我們程序里的數(shù)組�����,所以內(nèi)存的讀寫任何一個數(shù)據(jù)的速度都是一樣的。
中央處理器
中央處理器也就是我們常說的 CPU,32 位和 64 位 CPU 最主要區(qū)別在于一次能計(jì)算多少字節(jié)數(shù)據(jù):
這里的 32 位和 64 位���,通常稱為 CPU 的位寬。
之所以 CPU 要這樣設(shè)計(jì),是為了能計(jì)算更大的數(shù)值��,如果是 8 位的 CPU��,那么一次只能計(jì)算 1 個字節(jié) 0~255 范圍內(nèi)的數(shù)值���,這樣就無法一次完成計(jì)算 10000 * 500 ����,于是為了能一次計(jì)算大數(shù)的運(yùn)算����,CPU 需要支持多個 byte 一起計(jì)算,所以 CPU 位寬越大���,可以計(jì)算的數(shù)值就越大,比如說 32 位 CPU 能計(jì)算的最大整數(shù)是4294967295�。
CPU 內(nèi)部還有一些組件,常見的有寄存器����、控制單元和邏輯運(yùn)算單元等�。其中����,控制單元負(fù)責(zé)控制 CPU 工作,邏輯運(yùn)算單元負(fù)責(zé)計(jì)算�����,而寄存器可以分為多種類�����,每種寄存器的功能又不盡相同���。
CPU 中的寄存器主要作用是存儲計(jì)算時的數(shù)據(jù)�,你可能好奇為什么有了內(nèi)存還需要寄存器����?原因很簡單�����,因?yàn)閮?nèi)存離 CPU 太遠(yuǎn)了,而寄存器就在 CPU 里���,還緊挨著控制單元和邏輯運(yùn)算單元,自然計(jì)算時速度會很快����。
常見的寄存器種類:
通用寄存器,用來存放需要進(jìn)行運(yùn)算的數(shù)據(jù)���,比如需要進(jìn)行加和運(yùn)算的兩個數(shù)據(jù)。
程序計(jì)數(shù)器�����,用來存儲 CPU 要執(zhí)行下一條指令「所在的內(nèi)存地址」�,注意不是存儲了下一條要執(zhí)行的指令,此時指令還在內(nèi)存中���,程序計(jì)數(shù)器只是存儲了下一條指令的地址。
指令寄存器����,用來存放程序計(jì)數(shù)器指向的指令��,也就是指令本身,指令被執(zhí)行完成之前���,指令都存儲在這里。
總線
總線是用于 CPU 和內(nèi)存以及其他設(shè)備之間的通信���,總線可分為 3 種:
地址總線,用于指定 CPU 將要操作的內(nèi)存地址���;
數(shù)據(jù)總線,用于讀寫內(nèi)存的數(shù)據(jù)����;
控制總線����,用于發(fā)送和接收信號�����,比如中斷、設(shè)備復(fù)位等信號,CPU 收到信號后自然進(jìn)行響應(yīng)��,這時也需要控制總線����;
當(dāng) CPU 要讀寫內(nèi)存數(shù)據(jù)的時候,一般需要通過兩個總線:
輸入、輸出設(shè)備
輸入設(shè)備向計(jì)算機(jī)輸入數(shù)據(jù),計(jì)算機(jī)經(jīng)過計(jì)算后���,把數(shù)據(jù)輸出給輸出設(shè)備。期間,如果輸入設(shè)備是鍵盤�����,按下按鍵時是需要和 CPU 進(jìn)行交互的���,這時就需要用到控制總線了����。
線路位寬與 CPU 位寬
數(shù)據(jù)是如何通過線路傳輸?shù)哪兀科鋵?shí)是通過操作電壓,低電壓表示 0,高壓電壓則表示 1��。
如果構(gòu)造了高低高這樣的信號��,其實(shí)就是 101 二進(jìn)制數(shù)據(jù)���,十進(jìn)制則表示 5����,如果只有一條線路,就意味著每次只能傳遞 1 bit 的數(shù)據(jù),即 0 或 1,那么傳輸 101 這個數(shù)據(jù)�����,就需要 3 次才能傳輸完成����,這樣的效率非常低�。
這樣一位一位傳輸?shù)姆绞剑Q為串行,下一個 bit 必須等待上一個 bit 傳輸完成才能進(jìn)行傳輸����。當(dāng)然���,想一次多傳一些數(shù)據(jù)�,增加線路即可����,這時數(shù)據(jù)就可以并行傳輸。
為了避免低效率的串行傳輸?shù)姆绞剑€路的位寬最好一次就能訪問到所有的內(nèi)存地址�。CPU
要想操作的內(nèi)存地址就需要地址總線�,如果地址總線只有 1 條���,那每次只能表示 「0 或 1」這兩種情況����,所以 CPU 一次只能操作 2
個內(nèi)存地址,如果想要 CPU 操作 4G 的內(nèi)存�,那么就需要 32 條地址總線���,因?yàn)?2 ^ 32 = 4G����。
知道了線路位寬的意義后�����,我們再來看看 CPU 位寬����。
CPU
的位寬最好不要小于線路位寬��,比如 32 位 CPU 控制 40 位寬的地址總線和數(shù)據(jù)總線的話,工作起來就會非常復(fù)雜且麻煩�����,所以 32 位的
CPU 最好和 32 位寬的線路搭配�����,因?yàn)?32 位 CPU 一次最多只能操作 32 位寬的地址總線和數(shù)據(jù)總線����。
如果用
32 位 CPU 去加和兩個 64 位大小的數(shù)字��,就需要把這 2 個 64 位的數(shù)字分成 2 個低位 32 位數(shù)字和 2 個高位 32
位數(shù)字來計(jì)算�,先加個兩個低位的 32 位數(shù)字���,算出進(jìn)位��,然后加和兩個高位的 32 位數(shù)字�,最后再加上進(jìn)位�����,就能算出結(jié)果了�,可以發(fā)現(xiàn) 32 位
CPU 并不能一次性計(jì)算出加和兩個 64 位數(shù)字的結(jié)果�����。
對于 64 位 CPU 就可以一次性算出加和兩個 64 位數(shù)字的結(jié)果����,因?yàn)?64 位 CPU 可以一次讀入 64 位的數(shù)字��,并且 64 位 CPU 內(nèi)部的邏輯運(yùn)算單元也支持 64 位數(shù)字的計(jì)算�����。
但是并不代表 64 位 CPU 性能比 32 位 CPU 高很多,很少應(yīng)用需要算超過 32 位的數(shù)字����,所以如果計(jì)算的數(shù)額不超過 32 位數(shù)字的情況下���,32 位和 64 位 CPU 之間沒什么區(qū)別的����,只有當(dāng)計(jì)算超過 32 位數(shù)字的情況下�,64 位的優(yōu)勢才能體現(xiàn)出來。
另外�,32 位 CPU 最大只能操作 4GB 內(nèi)存���,就算你裝了 8 GB 內(nèi)存條�,也沒用����。而 64 位 CPU 尋址范圍則很大,理論最大的尋址空間為 2^64��。
程序執(zhí)行的基本過程
在前面�����,我們知道了程序在圖靈機(jī)的執(zhí)行過程�����,接下來我們來看看程序在馮諾依曼模型上是怎么執(zhí)行的����。
程序?qū)嶋H上是一條一條指令,所以程序的運(yùn)行過程就是把每一條指令一步一步的執(zhí)行起來,負(fù)責(zé)執(zhí)行指令的就是 CPU 了�。
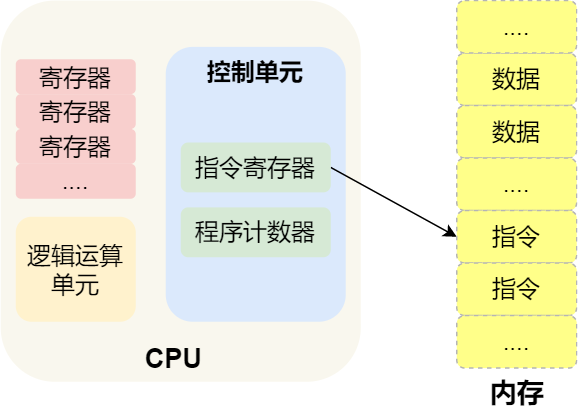
那 CPU 執(zhí)行程序的過程如下:
第一步���,CPU
讀取「程序計(jì)數(shù)器」的值���,這個值是指令的內(nèi)存地址�����,然后 CPU
的「控制單元」操作「地址總線」指定需要訪問的內(nèi)存地址,接著通知內(nèi)存設(shè)備準(zhǔn)備數(shù)據(jù)�����,數(shù)據(jù)準(zhǔn)備好后通過「數(shù)據(jù)總線」將指令數(shù)據(jù)傳給 CPU���,CPU
收到內(nèi)存?zhèn)鱽淼臄?shù)據(jù)后�����,將這個指令數(shù)據(jù)存入到「指令寄存器」����。
第二步����,CPU 分析「指令寄存器」中的指令�,確定指令的類型和參數(shù),如果是計(jì)算類型的指令��,就把指令交給「邏輯運(yùn)算單元」運(yùn)算�����;如果是存儲類型的指令��,則交由「控制單元」執(zhí)行�;
第三步����,CPU 執(zhí)行完指令后,「程序計(jì)數(shù)器」的值自增���,表示指向下一條指令。這個自增的大小��,由 CPU 的位寬決定���,比如 32 位的 CPU�����,指令是 4 個字節(jié)��,需要 4 個內(nèi)存地址存放,因此「程序計(jì)數(shù)器」的值會自增 4;
簡單總結(jié)一下就是,一個程序執(zhí)行的時候�����,CPU 會根據(jù)程序計(jì)數(shù)器里的內(nèi)存地址���,從內(nèi)存里面把需要執(zhí)行的指令讀取到指令寄存器里面執(zhí)行����,然后根據(jù)指令長度自增��,開始順序讀取下一條指令��。
CPU 從程序計(jì)數(shù)器讀取指令、到執(zhí)行��、再到下一條指令�,這個過程會不斷循環(huán),直到程序執(zhí)行結(jié)束����,這個不斷循環(huán)的過程被稱為 CPU 的指令周期���。
a = 1 + 2 執(zhí)行具體過程
知道了基本的程序執(zhí)行過程后����,接下來用 a = 1 + 2 的作為例子�,進(jìn)一步分析該程序在馮諾伊曼模型的執(zhí)行過程。
CPU 是不認(rèn)識 a = 1 + 2 這個字符串���,這些字符串只是方便我們程序員認(rèn)識,要想這段程序能跑起來�,還需要把整個程序翻譯成匯編語言的程序�����,這個過程稱為編譯成匯編代碼。
針對匯編代碼����,我們還需要用匯編器翻譯成機(jī)器碼���,這些機(jī)器碼由 0 和 1 組成的機(jī)器語言,這一條條機(jī)器碼,就是一條條的計(jì)算機(jī)指令���,這個才是 CPU 能夠真正認(rèn)識的東西。
下面來看看 a = 1 + 2 在 32 位 CPU 的執(zhí)行過程。
程序編譯過程中�,編譯器通過分析代碼���,發(fā)現(xiàn) 1 和 2 是數(shù)據(jù)��,于是程序運(yùn)行時,內(nèi)存會有個專門的區(qū)域來存放這些數(shù)據(jù),這個區(qū)域就是「數(shù)據(jù)段」。如下圖���,數(shù)據(jù) 1 和 2 的區(qū)域位置:
注意����,數(shù)據(jù)和指令是分開區(qū)域存放的���,存放指令區(qū)域的地方稱為「正文段」����。

編譯器會把 a = 1 + 2 翻譯成 4 條指令,存放到正文段中�。如圖��,這 4 條指令被存放到了 0x200 ~ 0x20c 的區(qū)域中:
0x200 的內(nèi)容是 load 指令將 0x100 地址中的數(shù)據(jù) 1 裝入到寄存器 R0;
0x204 的內(nèi)容是 load 指令將 0x104 地址中的數(shù)據(jù) 2 裝入到寄存器 R1����;
0x208 的內(nèi)容是 add 指令將寄存器 R0 和 R1 的數(shù)據(jù)相加����,并把結(jié)果存放到寄存器 R2���;
0x20c 的內(nèi)容是 store 指令將寄存器 R2 中的數(shù)據(jù)存回?cái)?shù)據(jù)段中的 0x108 地址中����,這個地址也就是變量 a 內(nèi)存中的地址��;
編譯完成后�,具體執(zhí)行程序的時候�,程序計(jì)數(shù)器會被設(shè)置為 0x200 地址,然后依次執(zhí)行這 4 條指令�。
上面的例子中�����,由于是在 32 位 CPU 執(zhí)行的,因此一條指令是占 32 位大小,所以你會發(fā)現(xiàn)每條指令間隔 4 個字節(jié)��。
而數(shù)據(jù)的大小是根據(jù)你在程序中指定的變量類型����,比如 int 類型的數(shù)據(jù)則占 4 個字節(jié),char 類型的數(shù)據(jù)則占 1 個字節(jié)。
指令
上面的例子中�����,圖中指令的內(nèi)容我寫的是簡易的匯編代碼���,目的是為了方便理解指令的具體內(nèi)容�,事實(shí)上指令的內(nèi)容是一串二進(jìn)制數(shù)字的機(jī)器碼,每條指令都有對應(yīng)的機(jī)器碼���,CPU 通過解析機(jī)器碼來知道指令的內(nèi)容。
不同的 CPU 有不同的指令集���,也就是對應(yīng)著不同的匯編語言和不同的機(jī)器碼,接下來選用最簡單的 MIPS 指集���,來看看機(jī)器碼是如何生成的����,這樣也能明白二進(jìn)制的機(jī)器碼的具體含義。
MIPS 的指令是一個 32 位的整數(shù)��,高 6 位代表著操作碼����,表示這條指令是一條什么樣的指令,剩下的 26 位不同指令類型所表示的內(nèi)容也就不相同��,主要有三種類型R���、I 和 J���。
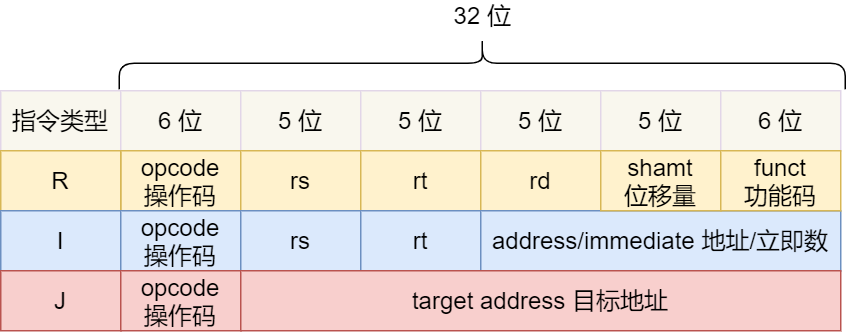
一起具體看看這三種類型的含義:
R 指令�,用在算術(shù)和邏輯操作,里面由讀取和寫入數(shù)據(jù)的寄存器地址��。如果是邏輯位移操作,后面還有位移操作的「位移量」��,而最后的「功能碼」則是再前面的操作碼不夠的時候����,擴(kuò)展操作碼來表示對應(yīng)的具體指令的;
I 指令����,用在數(shù)據(jù)傳輸�、條件分支等�。這個類型的指令,就沒有了位移量和操作碼�����,也沒有了第三個寄存器��,而是把這三部分直接合并成了一個地址值或一個常數(shù);
J 指令�,用在跳轉(zhuǎn)���,高 6 位之外的 26 位都是一個跳轉(zhuǎn)后的地址����;
接下來�����,我們把前面例子的這條指令:「add 指令將寄存器 R0 和 R1 的數(shù)據(jù)相加��,并把結(jié)果放入到 R3」,翻譯成機(jī)器碼����。

加和運(yùn)算 add 指令是屬于 R 指令類型:
add 對應(yīng)的 MIPS 指令里操作碼是 000000�����,以及最末尾的功能碼是100000,這些數(shù)值都是固定的����,查一下 MIPS 指令集的手冊就能知道的��;
rs 代表第一個寄存器 R0 的編號,即 00000�����;
rt 代表第二個寄存器 R1 的編號�����,即 00001;
rd 代表目標(biāo)的臨時寄存器 R2 的編號,即 00010;
因?yàn)椴皇俏灰撇僮鳎晕灰屏渴?00000
把上面這些數(shù)字拼在一起就是一條 32 位的 MIPS 加法指令了�,那么用 16 進(jìn)制表示的機(jī)器碼則是 0x00011020����。
編譯器在編譯程序的時候��,會構(gòu)造指令���,這個過程叫做指令的編碼�����。CPU 執(zhí)行程序的時候,就會解析指令,這個過程叫作指令的解碼。
現(xiàn)代大多數(shù) CPU 都使用來流水線的方式來執(zhí)行指令�,所謂的流水線就是把一個任務(wù)拆分成多個小任務(wù)����,于是一條指令通常分為 4 個階段�����,稱為 4 級流水線���,如下圖:
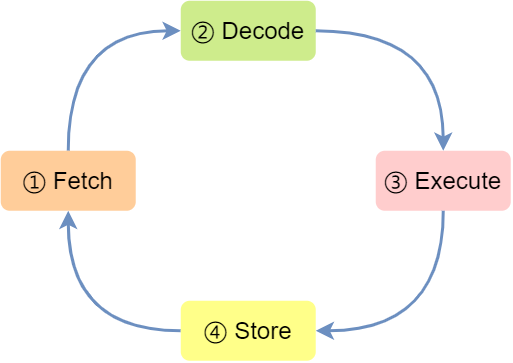
四個階段的具體含義:
CPU 通過程序計(jì)數(shù)器讀取對應(yīng)內(nèi)存地址的指令��,這個部分稱為 Fetch(取得指令)�;
CPU 對指令進(jìn)行解碼��,這個部分稱為 Decode(指令譯碼)�;
CPU 執(zhí)行指令����,這個部分稱為 Execution(執(zhí)行指令)���;
CPU 將計(jì)算結(jié)果存回寄存器或者將寄存器的值存入內(nèi)存�����,這個部分稱為Store(數(shù)據(jù)回寫)����;
上面這 4 個階段����,我們稱為指令周期(Instrution Cycle),CPU 的工作就是一個周期接著一個周期�����,周而復(fù)始��。
事實(shí)上���,不同的階段其實(shí)是由計(jì)算機(jī)中的不同組件完成的:

取指令的階段���,我們的指令是存放在存儲器里的��,實(shí)際上,通過程序計(jì)數(shù)器和指令寄存器取出指令的過程�,是由控制器操作的����;
指令的譯碼過程�,也是由控制器進(jìn)行的;
指令執(zhí)行的過程,無論是進(jìn)行算術(shù)操作�、邏輯操作�,還是進(jìn)行數(shù)據(jù)傳輸��、條件分支操作,都是由算術(shù)邏輯單元操作的��,也就是由運(yùn)算器處理的��。但是如果是一個簡單的無條件地址跳轉(zhuǎn)�����,則是直接在控制器里面完成的,不需要用到運(yùn)算器�。
指令的類型
指令從功能角度劃分����,可以分為 5 大類:
數(shù)據(jù)傳輸類型的指令���,比如 store/load 是寄存器與內(nèi)存間數(shù)據(jù)傳輸?shù)闹噶睿?code style="background: rgb(248, 248, 248); margin: 0px 2px; padding: 2px 4px; border-radius: 4px; color: rgb(248, 35, 117); line-height: inherit; font-family:;">mov 是將一個內(nèi)存地址的數(shù)據(jù)移動到另一個內(nèi)存地址的指令���;
運(yùn)算類型的指令��,比如加減乘除�����、位運(yùn)算、比較大小等等�����,它們最多只能處理兩個寄存器中的數(shù)據(jù)���;
跳轉(zhuǎn)類型的指令,通過修改程序計(jì)數(shù)器的值來達(dá)到跳轉(zhuǎn)執(zhí)行指令的過程�,比如編程中常見的 if-else���、swtich-case、函數(shù)調(diào)用等�����。
信號類型的指令�����,比如發(fā)生中斷的指令 trap��;
閑置類型的指令,比如指令 nop���,執(zhí)行后 CPU 會空轉(zhuǎn)一個周期;
指令的執(zhí)行速度
CPU 的硬件參數(shù)都會有 GHz 這個參數(shù)��,比如一個 1 GHz 的 CPU���,指的是時鐘頻率是 1 G����,代表著 1 秒會產(chǎn)生 1G 次數(shù)的脈沖信號,每一次脈沖信號高低電平的轉(zhuǎn)換就是一個周期�,稱為時鐘周期��。
對于 CPU 來說,在一個時鐘周期內(nèi)����,CPU 僅能完成一個最基本的動作�,時鐘頻率越高�,時鐘周期就越短,工作速度也就越快����。
一個時鐘周期一定能執(zhí)行完一條指令嗎?答案是不一定的,大多數(shù)指令不能在一個時鐘周期完成,通常需要若干個時鐘周期。不同的指令需要的時鐘周期是不同的���,加法和乘法都對應(yīng)著一條 CPU 指令,但是乘法需要的時鐘周期就要比加法多。
如何讓程序跑的更快����?
程序執(zhí)行的時候�����,耗費(fèi)的 CPU 時間少就說明程序是快的,對于程序的 CPU 執(zhí)行時間�����,我們可以拆解成 CPU 時鐘周期數(shù)(CPU Cycles)和時鐘周期時間(Clock Cycle Time)的乘積�。

時鐘周期時間就是我們前面提及的 CPU 主頻,主頻越高說明 CPU 的工作速度就越快���,比如我手頭上的電腦的 CPU 是 2.4 GHz 四核 Intel Core i5��,這里的 2.4 GHz 就是電腦的主頻�����,時鐘周期時間就是 1/2.4G�����。
要想 CPU 跑的更快,自然縮短時鐘周期時間,也就是提升 CPU 主頻,但是今非彼日,摩爾定律早已失效���,當(dāng)今的 CPU 主頻已經(jīng)很難再做到翻倍的效果了。
另外,換一個更好的 CPU����,這個也是我們軟件工程師控制不了的事情,我們應(yīng)該把目光放到另外一個乘法因子 —— CPU 時鐘周期數(shù)��,如果能減少程序所需的 CPU 時鐘周期數(shù)量,一樣也是能提升程序的性能的�����。
對于 CPU 時鐘周期數(shù)我們可以進(jìn)一步拆解成:「指令數(shù) x 每條指令的平均時鐘周期數(shù)(Cycles Per Instruction�,簡稱 CPI)」,于是程序的 CPU 執(zhí)行時間的公式可變成如下:

因此����,要想程序跑的更快�����,優(yōu)化這三者即可:
指令數(shù),表示執(zhí)行程序所需要多少條指令,以及哪些指令�����。這個層面是基本靠編譯器來優(yōu)化����,畢竟同樣的代碼,在不同的編譯器,編譯出來的計(jì)算機(jī)指令會有各種不同的表示方式。
每條指令的平均時鐘周期數(shù) CPI�����,表示一條指令需要多少個時鐘周期數(shù)����,現(xiàn)代大多數(shù) CPU 通過流水線技術(shù)(Pipline),讓一條指令需要的 CPU 時鐘周期數(shù)盡可能的少���;
時鐘周期時間,表示計(jì)算機(jī)主頻�����,取決于計(jì)算機(jī)硬件�。有的 CPU 支持超頻技術(shù)��,打開了超頻意味著把 CPU 內(nèi)部的時鐘給調(diào)快了����,于是 CPU 工作速度就變快了��,但是也是有代價(jià)的�,CPU 跑的越快����,散熱的壓力就會越大,CPU 會很容易奔潰�����。
很多廠商為了跑分而跑分����,基本都是在這三個方面入手的哦,特別是超頻這一塊����。
總結(jié)
最后我們再來回答開頭的問題��。
64 位相比 32 位 CPU 的優(yōu)勢在哪嗎?64 位 CPU 的計(jì)算性能一定比 32 位 CPU 高很多嗎�����?
64 位相比 32 位 CPU 的優(yōu)勢主要體現(xiàn)在兩個方面:
64 位 CPU 可以一次計(jì)算超過 32 位的數(shù)字�����,而 32 位 CPU 如果要計(jì)算超過 32 位的數(shù)字,要分多步驟進(jìn)行計(jì)算,效率就沒那么高,但是大部分應(yīng)用程序很少會計(jì)算那么大的數(shù)字,所以只有運(yùn)算大數(shù)字的時候��,64 位 CPU 的優(yōu)勢才能體現(xiàn)出來��,否則和 32 位 CPU 的計(jì)算性能相差不大���。
64 位 CPU 可以尋址更大的內(nèi)存空間���,32 位 CPU 最大的尋址地址是 4G����,即使你加了 8G 大小的內(nèi)存,也還是只能尋址到 4G��,而 64 位 CPU 最大尋址地址是 2^64���,遠(yuǎn)超于 32 位 CPU 最大尋址地址的 2^32��。
你知道軟件的 32 位和 64 位之間的區(qū)別嗎���?再來 32 位的操作系統(tǒng)可以運(yùn)行在 64 位的電腦上嗎�����?64 位的操作系統(tǒng)可以運(yùn)行在 32 位的電腦上嗎?如果不行���,原因是什么?
64 位和 32 位軟件,實(shí)際上代表指令是 64 位還是 32 位的:
如果 32 位指令在 64 位機(jī)器上執(zhí)行,需要一套兼容機(jī)制,就可以做到兼容運(yùn)行了。但是如果 64 位指令在 32 位機(jī)器上執(zhí)行��,就比較困難了����,因?yàn)?32 位的寄存器存不下 64 位的指令���;
操作系統(tǒng)其實(shí)也是一種程序�����,我們也會看到操作系統(tǒng)會分成 32 位操作系統(tǒng)����、64 位操作系統(tǒng)���,其代表意義就是操作系統(tǒng)中程序的指令是多少位�����,比如 64 位操作系統(tǒng)��,指令也就是 64 位,因此不能裝在 32 位機(jī)器上�����。
總之�,硬件的 64 位和 32 位指的是 CPU 的位寬,軟件的 64 位和 32 位指的是指令的位寬�����。
優(yōu)秀人工智能圖書推薦:

書號: 9787302556695
出版單位:清華大學(xué)出版社