1.全文本搜索和挖掘的搜索引擎
包括:搜索方法、技術(shù):全文本搜索,信息檢索,桌面搜索,企業(yè)搜索和分面搜索。
開源搜索工具:
■Open Semantic Search:專門用于搜索自己文件的搜索引擎,同樣的還有Open Semantic Desktop Search:可用于搜索單一一臺筆記本電腦或單一用戶的文件資源。
■InvestigateIX: 用于搜索加密外部設(shè)備
■Recoll: 適用于Linux系統(tǒng)的桌面搜索引擎
■Fuzzy search with lists:清單搜索、模糊搜索

搜索數(shù)據(jù)庫和API
■如果你想編程,你可以試用以下強大的搜索引擎:Solr和Elastic Search,支持索引和API搜索,更多全文搜索、實時檢索、數(shù)據(jù)分析、多格式數(shù)據(jù)讀取(JSON, SML, CSV或HTTP)等強大功能等你開發(fā)。
2.數(shù)據(jù)庫、數(shù)字文檔、數(shù)據(jù)管理系統(tǒng)、文件管理系統(tǒng)和內(nèi)容管理系統(tǒng)
■還在為不同格式的腳注、尾注、文中引用和文獻參考大費腦筋嗎?資源整理神器Zotero的標(biāo)注和引用功能幫你解決難題。它可以在Word,Open Office添加引用,在Google doc和電子郵件中插入文獻參考,或者為數(shù)據(jù)庫添加標(biāo)記。
■LibreOffice Calc:開源表格程序
■Document cloud:文檔管理系統(tǒng),管理紙質(zhì)文件掃描版本或者PDF 格式文件
■Semantic MediaWiki: MediaWiki(著名開源引擎,可用于構(gòu)建企業(yè)/個人知識庫,維基百科就是使用MediaWiki的成功范例)的免費開源擴展,可供用戶存儲、調(diào)用數(shù)據(jù)
■Drupal CMS:內(nèi)容管理模塊,可以讓你快速便捷地以用戶界面創(chuàng)制自己的內(nèi)容格式、數(shù)據(jù)字段和表格
■想從大量文件中單獨抽取金額來分析?專業(yè)的文件管理系統(tǒng)Agorum可以自動從賬單抽取金錢數(shù)額,幫你輕松解決。
■想標(biāo)記圖片中的文字?Pundit幫你辦到,它同時支持文本和圖片標(biāo)記。
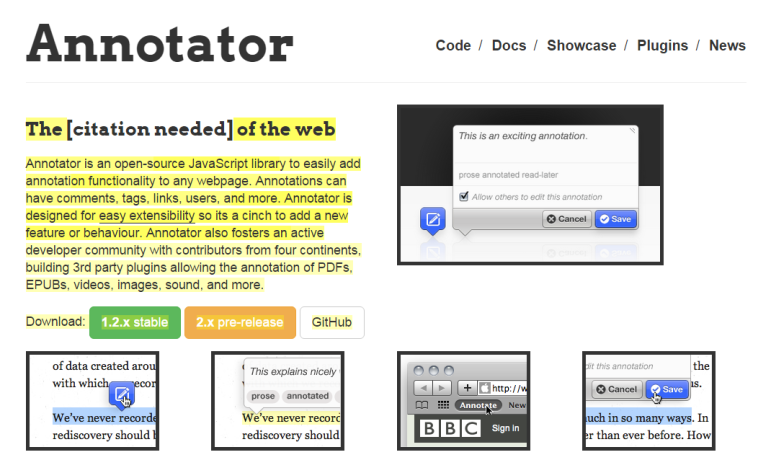
■想在網(wǎng)站加注釋?Annotator.js幫你在任何網(wǎng)頁加注釋,而且可以添加評論、標(biāo)簽、鏈接、用戶或者更多不同種類的信息,第三方插件還能幫你在難以搞定的PDF、EPUB、視頻、圖片、聲音甚至更多格式的文件上添加標(biāo)注。
■標(biāo)注了信息,想收到更新提醒?Hypothesis可供用戶訂閱一系列已標(biāo)注的活動信息,而且能按照自己的興趣獲取通知,而且還能分享評注、鏈接詞典。程序員還可以獲取有限的網(wǎng)站許可,通過第三方應(yīng)用創(chuàng)建、更新、刪除、搜索注釋。
3. 文本文件挖掘、分析
■Text mining tutorial: How to analyze large document collections:文本挖掘教程:如何分析大容量文件集(使用Open Semantic Search來挖掘文本)
■Understanding language data: 理解語言數(shù)據(jù):可以使用開源NLP(自然語言處理)軟件
■統(tǒng)計詞頻有困難?Overview project可以顯示文本最常用的詞和它們的詞群分布
■想以圖解的方式查看文本檢索結(jié)果?文本搜索工具Jigsaw:(非開源軟件,但可免費下載)可統(tǒng)計文本中最重要的人物、地點、組織等實體的出現(xiàn)頻率,并將他們之間的關(guān)系以列表、圖表、時間表和關(guān)系圖的形式呈現(xiàn)出來,提高文本分析效率。
■Wikipedia list of open source text mining software:維基百科上整合的開源文本挖掘軟件列表
■Tapor: 研究專用的文本分析門戶,提供大量文本分析工具,你可以按照類型或標(biāo)記找到最適合的一款。

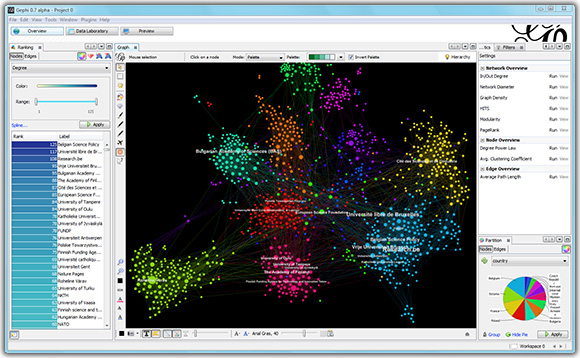
4. 圖表和關(guān)系網(wǎng)絡(luò)分析(SNA)
幫助分析關(guān)聯(lián)并將其可視化的工具:
■關(guān)系網(wǎng)分析教程:教你如何用Open Semantic Search可視化關(guān)聯(lián)
■Cytoscape.js: Javascript數(shù)據(jù)庫,能將關(guān)系網(wǎng)、事物分屬和圖表可視化
■Semantic Mediawiki:上面介紹過,不僅是數(shù)據(jù)庫,也是適用于關(guān)聯(lián)數(shù)據(jù)、非常靈活的內(nèi)容管理系統(tǒng)
■Detective: 以Python/Django和neo4j圖像數(shù)據(jù)庫為基礎(chǔ)的內(nèi)容管理系統(tǒng),適用于分析關(guān)系。
5. 抽取、轉(zhuǎn)換數(shù)據(jù)
包括數(shù)據(jù)整合、抽取、轉(zhuǎn)換、轉(zhuǎn)移、ETL(數(shù)據(jù)提取、轉(zhuǎn)換和加載)網(wǎng)絡(luò)爬蟲采集等等。
從文件抽取結(jié)構(gòu)化數(shù)據(jù):
■Tika content analysis toolkit: 從文檔和文件抽取文本和元數(shù)據(jù)
■CSV Manager:將csv表格輸入Solr為基礎(chǔ)的搜索引擎
■想從PDF文件抽取數(shù)據(jù)、轉(zhuǎn)化為可編輯的文本?免費軟件Tabula可以直接從PDF文件抽取數(shù)據(jù)表格,神奇吧
■圖片識別和文本掃描:光學(xué)字符識別(OCR)
從圖片識別文本(OCR):
■Tesseract: 光學(xué)識別軟件,從圖片識別文本
■低質(zhì)量掃描沒法看?Scantailor幫你分頁、矯正文本、添加/刪除頁邊,可以將原始文本傳換成PDF或者DJVU格式的文件,便于打印。

從聲音識別、抽取文本:
■CMU Sphinx: 開源聲音識別工具,支持英語、法語、中文、德語、荷蘭語、俄語。該開發(fā)商還提供關(guān)鍵詞識別和讀音識別等實用工具,可以多多關(guān)注。

從網(wǎng)站抽取數(shù)據(jù)(網(wǎng)絡(luò)信息采集/網(wǎng)絡(luò)爬蟲):
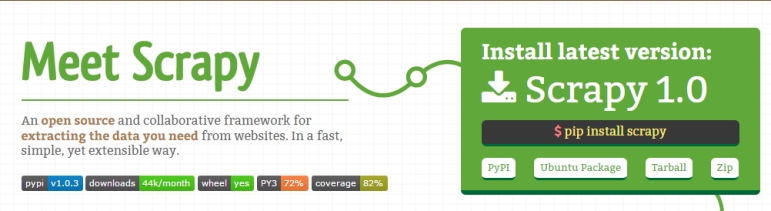
■網(wǎng)絡(luò)采集哪家強?簡易 Scrapy幫你忙:你可以依托Scrapy建立自己的網(wǎng)絡(luò)爬蟲工具,編寫Python代碼,在Windows,Mac,Linux和BSD系統(tǒng)上都可運行。
6. 輸入、修改、轉(zhuǎn)換數(shù)據(jù)
■將數(shù)據(jù)轉(zhuǎn)換成純文本的超強工具: Tika content analysis toolkit
■將數(shù)據(jù)轉(zhuǎn)換成其他格式的工具:Talend Open Studio和Kettle
編寫文件和刪除元數(shù)據(jù):
記者為了保護信息,往往需要編寫文件、清除敏感文件、刪除隱藏在文件或圖片里的元數(shù)據(jù),例如軟件的序列號或軟件、用戶名,以下工具可供參考
■PDF Redact Tools: 以最安全的方式刪除PDF中的元數(shù)據(jù)
■MAT: Metadata Anonymisation Toolkit:從不同的文件格式和圖片格式中刪除元數(shù)據(jù)

7. 統(tǒng)計與分析
包括數(shù)據(jù)分析、統(tǒng)計、圖表、數(shù)據(jù)可視化。
■開源表格程序LibreOffice Calc
■上面介紹過的HUE Solr search和Kibana for Elastic Search,除了能檢索數(shù)據(jù)庫和API,也能完成數(shù)據(jù)分析
■適用于數(shù)據(jù)分析和計量經(jīng)濟分析的專業(yè)電腦程序:Statistical software
■統(tǒng)計和分析的工具大全:Business Intelligence
■用R 、 Python或其他編程語言編程分析數(shù)據(jù)
■以上數(shù)據(jù)分析太復(fù)雜?剛?cè)腴T,想理解數(shù)據(jù)分析原理?推薦閱讀解釋數(shù)據(jù)挖掘方法的書Mining of massive datasets


8. 通用開源軟件工具包
最強大的通用開源工具包,例如 Debian GNU/Linux或Ubuntu Linux,涵蓋了成千上萬個免費軟件和開源工具、軟件數(shù)據(jù)庫和編程語言。
運行時,用戶無需移除現(xiàn)有的操作系統(tǒng):安裝適用于Windows和Mac的Virtual Box,你就可以在現(xiàn)有操作環(huán)境下的單獨的窗口運行上述Linux軟件。